When to use
After an agent acts, users ask "why did it do that?" and need a clear answer.
Example scenario: CRM agent flags a lead; expandable panel cites growth % and pricing page visits.
Anatomy
UI pieces that make this pattern recognizable.
- Expandable 'Why?' on the action or recommendation card
- Bulleted reasons tied to named inputs
- Optional link to source records or diffs
Guidance
Do
- Lead with the top reason; detail on expand
- Use the user's vocabulary (account names, dates, policies)
Avoid
- Do not use opaque 'the model decided' messaging
- Do not hide rationale in developer consoles only
Limitations
When this pattern adds friction or fails to help.
- Post-hoc rationales can sound plausible without being faithful to the model's actual reasoning
- Too much explanation on every micro-action creates noise
- Users may treat rationale as proof without verifying linked sources
Build notes
Implementation hints for engineers shipping the pattern.
- Generate rationale from structured decision metadata
- Allow users to flag incorrect rationale for feedback loops
Examples
Annotated screenshots from production products, with designer critique.
Claude Deep Research
Source breakdown by query
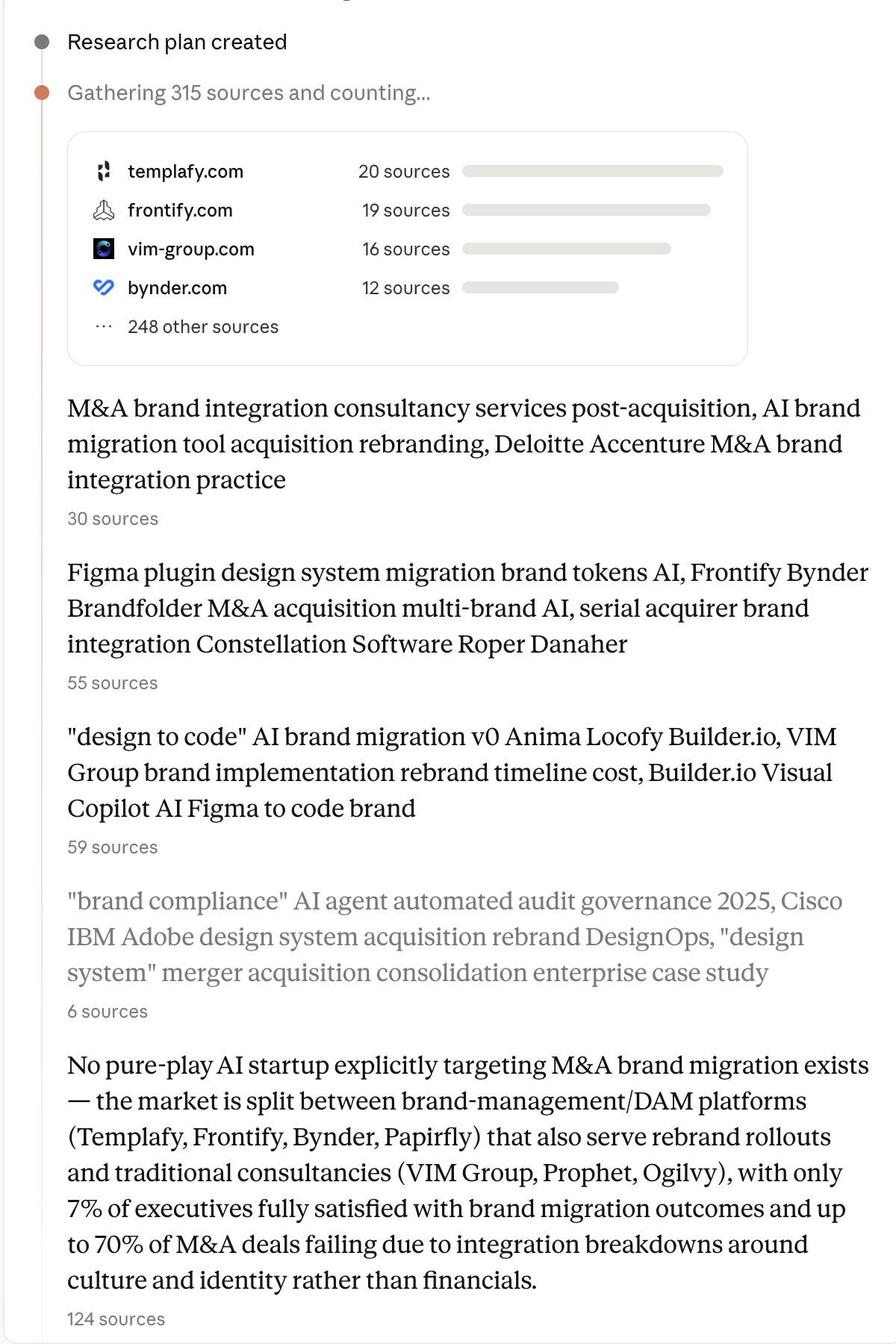
Context
While research runs, Claude exposes a side panel grouping findings by search thread—each with source counts, top domains (Templafy, Frontify), and synthesis paragraphs citing how many sources support each claim.
What works
- Named domains and counts make evidence inspectable
- Threads map to user-facing research themes, not raw queries
- Synthesis cites source volume ('124 sources') for major claims
What to improve
- Individual citations still require expanding threads
- Fact-check pass is separate from initial synthesis
Takeaway: Long-run agents should show where knowledge came from as the run proceeds—not only in the final report.
Claude Deep Research
Cited synthesis with fact-check pass
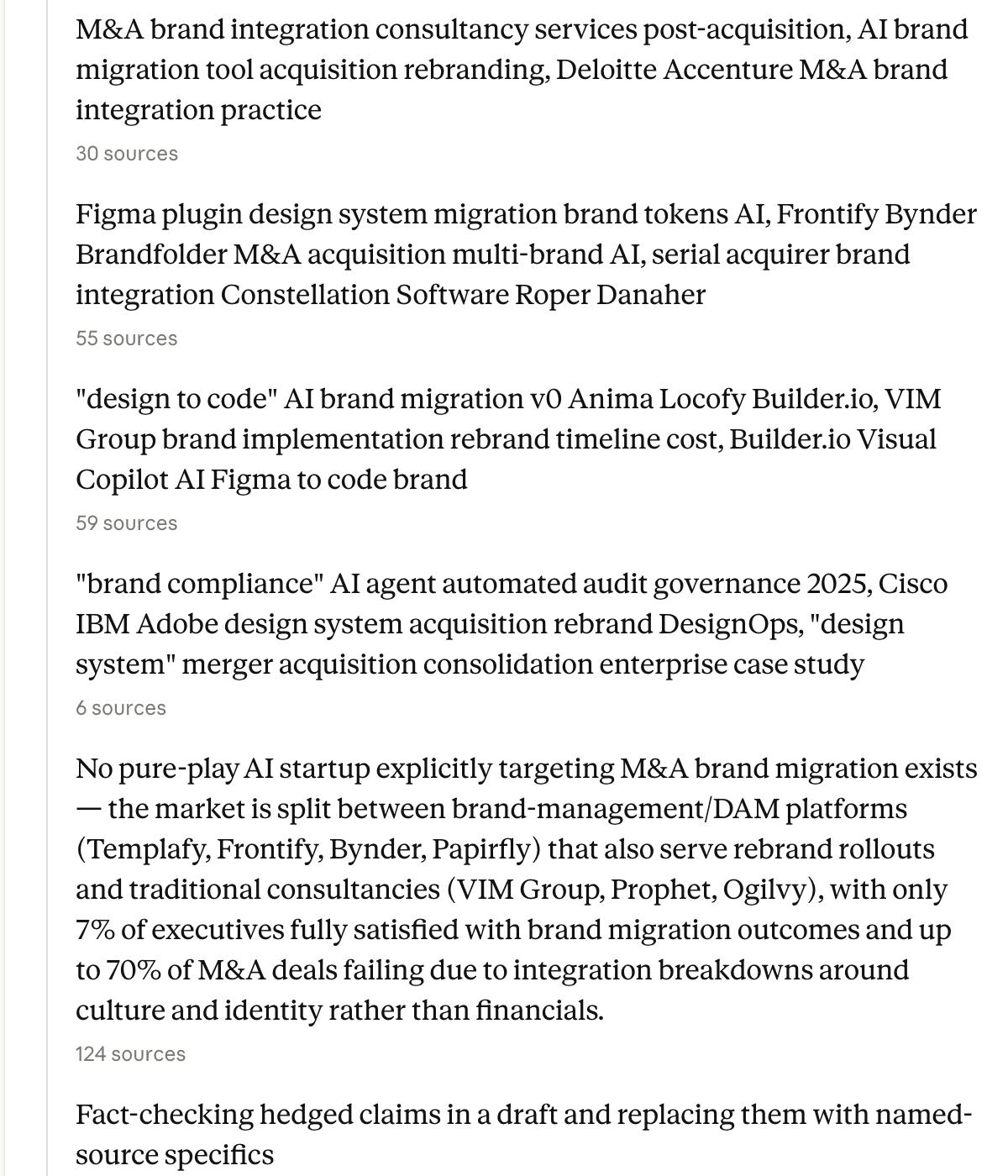
Context
Late in a research run, Claude surfaces a synthesis block naming market structure (DAM platforms vs consultancies), hedged statistics (7% executive satisfaction), and a separate fact-checking pass on draft claims—each tied to source counts.
What works
- Claims carry explicit source counts users can challenge
- Fact-check step signals epistemic humility on hedged stats
- Plain-language synthesis precedes the formal report
What to improve
- Inline footnotes would reduce panel-hunting
- Confidence language on statistics could be clearer
Takeaway: Explainability for research agents means traceable claims during synthesis—not a post-hoc 'Sources' footer only.